
| Version 3 (modified by , 10 years ago) ( diff ) |
|---|
SAM/BAM quality control
Analyzing short read quality (after mapping)
Remove Duplicates
- Remove duplicates, for eg. from PCR
#samtools command samtools rmdup [-sS] <input.srt.bam> <output.bam> -s or -S depending on PE data or not
Determining the paired-end insert size for DNA samples
If paired-end insert size or distance is unknown or need to be verified, it can be extracted from a BAM/SAM file after running Bowtie.
When mapping with bowtie (or another mapper), the insert size can often be included as an input parameter (example for bowtie: -X 500), which can help with mapping. See the mapping SOP for mapping details.
Method 1: Get insert sizes from BAM file
# Using a SAM file (at Unix command prompt)
awk -F "\t" '$9 > 0 {print $9}' s_1_bowtie.sam > s_1_insert_sizes.txt
# Using a BAM file (at Unix command prompt)
samtools view s_1_bowtie.bam | awk -F"\t" '$9 > 0 {print $9}' > s_1_insert_sizes.txt
# and then process column of numbers with R (or Excel)
# In R Session
sizeFile = "s_1_insert_sizes.txt"
sample.name = "My paired reads"
distance = read.delim(sizeFile, h=F)[,1]
pdf(paste(sample.name, "insert.size.histogram.pdf", sep="."), w=11, h=8.5)
hist(distance, breaks=200, col="wheat", main=paste("Insert sizes for", sample.name), xlab="length (nt)")
dev.off()
Method 2: Calculate insert sizes with CollectInsertSizeMetrics function from picard (http://picard.sourceforge.net). This is also a good approximation for RNA samples.
# # I=File Input SAM or BAM file. (Required) # O=File File to write the output to. (Required) # H=File File to write insert size histogram chart to. (Required) # output: CollectInsertSizeMetrics.txt: values for -r and --mate-std-dev can be found in this text file # CollectInsertSizeMetrics_hist.pdf: insert size histogram (graphic representation) bsub java -jar /usr/local/share/picard-tools/CollectInsertSizeMetrics.jar I=foo.bam O=CollectInsertSizeMetrics.txt H=CollectInsertSizeMetrics_hist.pdf
Quality control after mapping
QC to get a (visual) summary of mapping statistics. For eg. coverage/distribution of mapped reads across the genome or transcriptome
| Picard: CollectRnaSeqMetrics.jar to find coverage across gene body for 5' or 3' bias
[RNA-seq only] Get global coverage profile across transcripts
Do reads come from across the length of a typical transcript, or is there 3' or 5' bias (where most reads come from one end of a typical transcript)?
One way to look at this is with Picard's CollectRnaSeqMetrics tool
# Usage: java -jar /usr/local/share/picard-tools/CollectRnaSeqMetrics.jar INPUT=bamFile REF_FLAT=refFlatFile STRAND_SPECIFICITY=NONE OUTPUT=outputFile REFERENCE_SEQUENCE=/path/to/genome.fa CHART_OUTPUT=output.pdf VALIDATION_STRINGENCY=SILENT # Example command java -jar /usr/local/share/picard-tools/CollectRnaSeqMetrics.jar INPUT=WT.bam REF_FLAT=/nfs/genomes/mouse_mm10_dec_11_no_random/anno/refFlat.txt STRAND_SPECIFICITY=NONE OUTPUT=QC_metrics/WT.RnaSeqMetrics.txt REFERENCE_SEQUENCE=/nfs/genomes/mouse_mm10_dec_11_no_random/fasta_whole_genome/mm10.fa CHART_OUTPUT=QC_metrics/WT.RnaSeqMetrics.pdf VALIDATION_STRINGENCY=SILENT
The VALIDATION_STRINGENCY=SILENT option will keep the program from crashing if it finds something unexpected. The default: VALIDATION_STRINGENCY=STRICT
| QualiMap: can be used on DNA or RNA-Seq to get summary of mapping and coverage/distribution
# Graphical interface: enter 'qualimap' on the command line # Command line: unset DISPLAY #needed for submitting to cluster bsub "qualimap bamqc -bam myFile.bam -outdir output_qualimap" # For huge data, you can increase memory with --java-mem-size="4800M" to avoid OutOfMemoryError: Java heap space #rnaseq qc bsub "qualimap rnaseq -bam myFile.bam -gtf Homo_sapiens.GRCh37.72.canonical.gtf -outdir output_qualimap_rnaseq -p non-strand-specific" #counts qc (after using htseq-count or similar program to generate a matrix of counts) qualimap counts -d countsqc_input.txt -c -s HUMAN -outdir counts_qc #Format of countsqc_input.txt (below), totalCounts.txt is a matrix of counts; header lines must be commented "#" and species is human or mouse only. #Sample Condition Path Column HMLE1 HMLE totalCounts.txt 2 HMLE2 HMLE totalCounts.txt 3 HMLE3 HMLE totalCounts.txt 4 N81 N8 totalCounts.txt 5 N82 N8 totalCounts.txt 6 N83 N8 totalCounts.txt 7
| RSeQC: RNA-Seq quality control package for getting mapping statistics (eg. unique/multi-mapped reads)
bam_stat.py -i myFile.bam
infer_experiment.py from RseQC package: can be used to check if the RNA-seq reads are stranded.
# Command line:
bsub infer_experiment.py -i accepted_hits.bam -r hs.bed
-i INPUT_FILE in SAM or BAM format
-r Reference gene model in bed fomat.
# sample output on strand-specific PE reads:
This is PairEnd Data
Fraction of reads explained by "1++,1--,2+-,2-+": 0.0193
Fraction of reads explained by "1+-,1-+,2++,2--": 0.9807
Fraction of reads explained by other combinations: 0.0000
# sample output on non-stranded PE reads:
This is PairEnd Data
Fraction of reads explained by "1++,1--,2+-,2-+": 0.5103
Fraction of reads explained by "1+-,1-+,2++,2--": 0.4897
Fraction of reads explained by other combinations: 0.0000
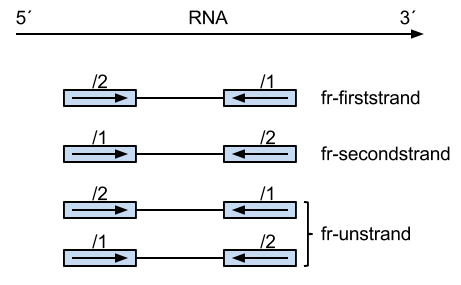
For pair-end RNA-seq, there are two different ways to strand reads:
i) 1++,1--,2+-,2-+
read1 mapped to '+' strand indicates parental gene on '+' strand
read1 mapped to '-' strand indicates parental gene on '-' strand
read2 mapped to '+' strand indicates parental gene on '-' strand
read2 mapped to '-' strand indicates parental gene on '+' strand
ii) 1+-,1-+,2++,2--
read1 mapped to '+' strand indicates parental gene on '-' strand
read1 mapped to '-' strand indicates parental gene on '+' strand
read2 mapped to '+' strand indicates parental gene on '+' strand
read2 mapped to '-' strand indicates parental gene on '-' strand
For single-end RNA-seq, there are two different ways to strand reads:
i) ++,--
read mapped to '+' strand indicates parental gene on '+' strand
read mapped to '-' strand indicates parental gene on '-' strand
ii) +-,-+
read mapped to '+' strand indicates parental gene on '-' strand
read mapped to '-' strand indicates parental gene on '+' strand
Interpreting quality control issues
See QC Fail Sequencing from the Babraham Institute
Attachments (1)
- tophat_library.png (11.8 KB ) - added by 10 years ago.
{kind=link}
{kind=link}
Download all attachments as: .zip